This section primarily describes the processing flow of the entire system.
Figure 4 illustrates the system architecture, showing that the system consists of four core modules:
- Sequential-update ESIKF
- Local map construction
- LiDAR observation model
- Visual observation model
Specifically, Module 1 deals with the ESIKF’s state prediction/update equations, while Modules 3 and 4 define the state observation equations of the ESIKF.
The processing flow is as follows: LiDAR points sampled asynchronously are merged to align with the camera’s sampling timestamps → Sequential updates are performed using ESIKF (first LiDAR, then camera). Both sensor modalities utilize a voxel map for management.
The LiDAR observation model performs frame-to-map point-to-plane residual calculations.
Visual map points within the current Field of View (FoV) are extracted from the voxel map using visible voxel queries and on-demand ray casting. Photometric errors (frame-to-map residuals, meaning the variation of photometric error between current and reference frames under pose perturbation ) are computed, enabling visual updates.
Local map maintenance: LiDAR-Inertial Odometry (LIO) updates geometric information of the voxel map, whereas Visual-Inertial Odometry (VIO) updates the current and reference image patches associated with the visual map points. (Updated reference image patches are further refined to obtain their normals in a separate thread.)
Sequential-update ESIKF
f readers are already familiar with ESIKF or the FAST-LIO system, this section can be skipped. However, for those unfamiliar, this section provides a step-by-step introduction to ESIKF.
This section introduces the mathematical models for state prediction and update, structured into four subsections: S
- Notation and State Transition Model
- Scan Recombination
- Propagation (Forward and Backward Propagation)
- Sequential Updates
Notation and State Transition Model
First, sensor coordinate frames are defined:
(Note: Only IMU and global frames are defined here since the entire system state is IMU-centric. Observations from LiDAR and camera are transformed into the IMU frame.) Next, the discrete-time state transition equation is given by:
- is the state vector
- represents IMU observations
- is the process noise
- is the IMU sampling interval
- is the kinematic equation matrix (Note: When deriving the state-space equations, some methods begin by differentiating the kinematic equations in continuous time to obtain continuous-time state-space equations, which are then discretized. Discretization typically involves either Euler integration or midpoint integration. This process can be tedious, as continuous-time equations must first be obtained. A more convenient alternative is to directly discretize the kinematic equations and derive discrete-time state-space equations directly. Readers are encouraged to refer to additional blogs for further details on state-space equation derivations.)
- I have also translated + added more explainations here:
Explanation of the operator:
Readers who have only read the FAST-LIVO2 paper may wonder what the symbol represents. In fact, it’s not complicated. This operator is explained clearly in the paper “FAST-LIO: A Fast, Robust LiDAR-Inertial Odometry Package by Tightly-Coupled Iterated Kalman Filter.” The operator arises primarily because rotation matrices do not form a closed group under standard addition. Simply put, consider a coordinate frame F undergoing rotations followed by , resulting in rotation . In this case, the relationship is , but rather . Thus, the standard addition operator (+) becomes inappropriate for representing rotation increments. Hence, the operator is introduced to suitably represent “addition” operations involving both the rotation space and the Euclidean space .
(Note: This explanation is a simplified interpretation. To thoroughly understand addition and subtraction operations in , readers are encouraged to further explore concepts related to manifolds and Rodrigues’ formula in sources like “Autonomous Driving and SLAM Technology in Robotics” or “14 Lectures on Visual SLAM” by Gao Xiang.)
Scan recombination
At the camera sampling timestamps, the high-frequency and sequentially sampled raw LiDAR points are segmented into different LiDAR scans. This ensures that camera and LiDAR data are synchronized at the same frequency (e.g., 10 Hz), enabling simultaneous state updates.
Author’s explanatory note:
Let me share my initial understanding, followed by my updated comprehension after reading the code.
-
Initial understanding:
Having some prior knowledge about LiDAR, I initially thought scan recombination meant that LiDAR doesn’t capture all points simultaneously, but sequentially, point by point. For example, capturing a single frame of 24,000 points takes 100 ms, beginning at time (the frame header time), and finishing at time . These points are then merged into one frame. I assumed this recombination process was what the authors meant by “scan Recombination,” but I later realized this wasn’t correct. -
Understanding after code analysis:
Because the camera’s trigger and exposure times aren’t perfectly stable, the exact LiDAR points corresponding to the camera’s capture time must be identified. Thus, each LiDAR point’s timestamp is evaluated individually: points timestamped before the camera’s capture time are classified as belonging to the current frame, while those after are attributed to the next frame. This process is actually what “scan recombination” refers to.
Additional note:
When reproducing results or reading the source code, readers might be confused by the additional 100 ms offset added to camera timestamps in the source code. Let me explain this based on my personal understanding:
- At time , the LiDAR begins capturing points, but initially, only the first point is captured.
- At time , the LiDAR completes the capture of an entire frame, and simultaneously, the camera captures an image.
- The camera driver then uses a shared timestamp file (a file created by Dr. Zheng himself to store the header timestamp of each point cloud frame) to assign the LiDAR’s frame header timestamp () to the camera frame as its timestamp.
- However, the camera data was actually captured at , meaning there’s an inherent 100 ms offset between the original LiDAR timestamp and the assigned camera timestamp. This explains the additional 100 ms time offset present in the source code.
Propagation
Forward Propagation
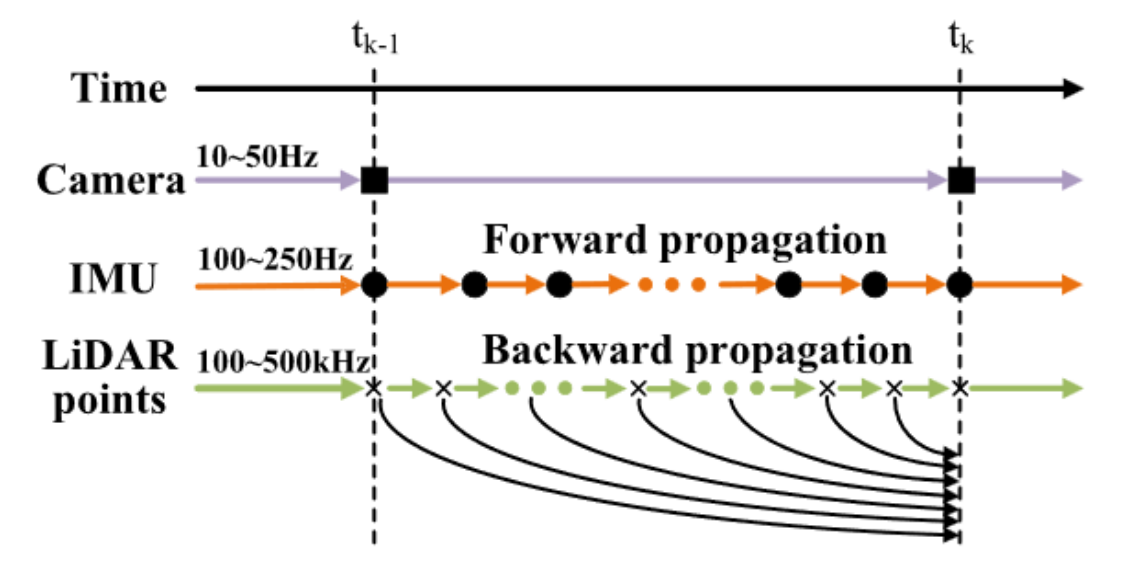 Forward propagation is essentially the prediction step of an Extended Kalman Filter (EKF): during this prediction phase, the process noise (which is unknown) is assumed to be zero. The system predicts states between times and using IMU measurements. After EKF prediction, we obtain the predicted state vector and its corresponding covariance, which serves as the prior for the update step.
Forward propagation is essentially the prediction step of an Extended Kalman Filter (EKF): during this prediction phase, the process noise (which is unknown) is assumed to be zero. The system predicts states between times and using IMU measurements. After EKF prediction, we obtain the predicted state vector and its corresponding covariance, which serves as the prior for the update step.
Readers might be curious about how the state transition Jacobian matrices and are derived. Here, I recommend a blog, which clearly and simply explains the derivation and explicit forms of these state coefficient matrices.
Backward propagation
Backward propagation is essentially a correction for LiDAR motion distortion, ensuring that all points within a LiDAR scan are effectively observed at the same timestamp .
What is Motion Distortion? As discussed in a Livox blog, motion distortion in LiDAR point clouds occurs because each point within a single LiDAR scan frame is captured under a slightly different coordinate system due to sensor movement. For instance, during a single frame interval, the LiDAR might be rapidly moving, thus capturing different points from different sensor poses. Consequently, points that should be collinear appear distorted because they reside in different coordinate frames:
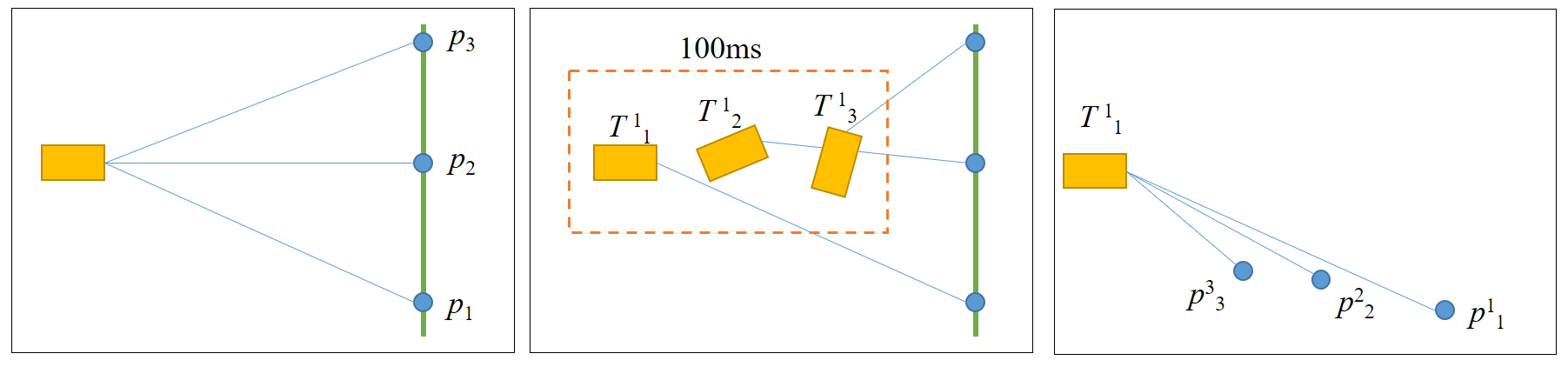 figure 6: Motion distortion example
figure 6: Motion distortion example
The solution: for each point between and , determine the transformation matrix relative to timestamp . (This was describe in the FAST-LIO paper)
Step-by-step Explanation:
- First, the state transition equation for backward propagation is established as:
- with the pose at as the initial reference pose. Here, is the time interval between LiDAR points.
- Next, LiDAR points between and are segmented according to IMU sampling intervals. A LiDAR point with timestamp belongs to some interval defined by two consecutive IMU samples.
- Example: A 10 Hz LiDAR (e.g., Livox Avia) generates 24,000 points per frame (100 ms), and a 200 Hz IMU generates 20 measurements in that same interval. Thus, multiple LiDAR points exist between any two IMU samples.
- Then, compute the transformation matrices at each timestamp relative to timestamp :
- Rotation Matrix at timestamp relative to ,
- Note: Within interval , the angular velocity is assumed constant, approximated by the IMU angular velocity at . The bias is fixed at the prior at .
- Velocity at timestamp relative to :
- Acceleration within this interval is assumed constant, equal to the IMU acceleration at . Acceleration biases and gravity are assumed fixed at their prior values at .
- Translation at timestamp relative to :
- Using computed velocities and accelerations, translation is calculated accordingly.
Finally, transforming each LiDAR point yields the corrected (undistorted) points at timestamp :