translated from: https://blog.csdn.net/qq_42731705/article/details/129420739
Intro example
when given different measurement devices, how can we obtain the diameter of a coin?
Test 1: Measuring tape
we can use the measuring tape to measure the diameter of the radius twice, measurements and . Taking the average gives the estimate
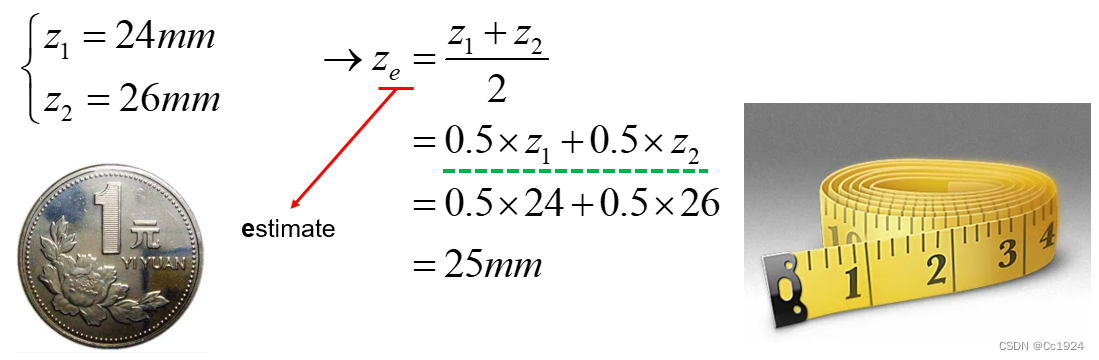
Test 2: measuring tape + ruler of different resolutions
To obtain the estimate would we still average the measurements?

Test 3: measuring tape and micro meter
In this case, would we still take one measurement each and take the average? Even though the micrometer’s resolution is much higher than the measuring tape? (1mm vs 0.001mm)

Intuition: No
Obviously, since sensor precisions differ, we can no longer simply average the readings from different sensors. Because, neglecting systematic error, a micrometer’s measurement is clearly more accurate than that of a tape measure.
So how can we obtain the best estimate of the coin’s diameter from measurements made by different sensors? That’s where the data‐fusion methods described later come in!
Data fusion
What does Data fusion do?
Using different sensors to achieve the best estimate of the system. In the example above, it would be to use different sensors (measuring devices) to give a best estimation of the coin’s diameter.
Prerequisite for Data Fusion — Uncertainty
No sensor is perfectly accurate, nor is there any measurement process that is completely error‑free. In other words, every single measurement comes with some uncertainty. When we ignore systematic errors, a higher‑precision sensor will have a smaller measurement uncertainty. For example, in the case above, the measurement uncertainty of the micrometer is much smaller than that of the tape measure.
In statistics, uncertainty is expressed in terms of standard deviation, variance, and the covariance matrix. Clearly, in the previous example, when computing a weighted average of measurements from different sensors, we should take each sensor’s uncertainty into account: the smaller the uncertainty, the larger the weight its measurement should carry, because it is more accurate.
 If we know the standard deviation of the measurements produced by each sensor, we should be able to derive a weight in order to assign different weights (importance/trustworthiness) to each measurement.
If we know the standard deviation of the measurements produced by each sensor, we should be able to derive a weight in order to assign different weights (importance/trustworthiness) to each measurement.
Result of Data Fusion: The Statistically Optimal Estimate
Every measurement carries uncertainty, so from a statistical standpoint our measurement is a random variable, and the final estimate of the system state is also a random variable. The optimal data‐fusion result, therefore, should minimize variance; for a multivariate random variable this means achieving the smallest possible trace of the covariance matrix.
Hence, when we derive the weighted average of the measurements from different sensors below, our goal is to choose weights so that the resulting weighted average has the minimum variance.
- Optimal Estimation: fusion result with the minimum uncertainty, i.e minimum
Example
Suppose we have measurements:
goal: to find value such that the estimation has minimal uncertainty
ans: recall that
due to properties of variance, we have
since and are constants in this case, we can differentiate with respect to to find the minima.
The result is easy to interpret in two scenarios:
- If is very large, then tends toward 1, and the fused result approaches . This makes sense: measurement 1 has a large variance (i.e., is less accurate), so we lean on measurement 2.
- If is very large, then tends toward 0, and the fused result approaches . The reasoning is analogous.
Plugging our derived formula into the previous example of measuring the coin’s diameter with a tape measure and a micrometer, we find that the final fused estimate lies very close to the micrometer’s reading, which is exactly the desirable outcome.

State Space Representation
In robotic state‑estimation problems, it’s not simply a matter of taking two sensor measurements and fusing them. Instead, one usually builds a motion model of the system that lets us predict its state. When new sensor data arrives, we update that prediction based on the measurements, yielding a more accurate estimate of the system state.
This process is precisely the system’s state‑space formulation. In the Kalman Filter, it’s broken into two parts: the state equation and the observation (measurement) equation.
State equation
We construct a mathematical model of the system’s physics. For example, in SLAM, if we assume the robot travels at constant velocity or under constant acceleration, then our models become the constant‑velocity model or the constant‑acceleration model, respectively.
In short, the state equation is something we calculate or derive. Given the system state at the previous time step, we use the state equation to compute the current system state, this constitutes our prediction.
Another point to note, as mentioned in the Data Fusion section, is that both measurements and our mathematical model carry uncertainty. For instance, our model may be imperfect, so the state equation is subject to noise. In the Kalman Filter, we assume this noise is Gaussian, an essential premise for deriving the Kalman Gain.
- : state‑transition matrix
- : control‑input matrix
- : control vector
- : process noise, assumed to be drawn from multivariate normal distribution with zero‑mean and covariance
: State‑Transition Matrix
- What it is: A matrix that encodes your system’s built‑in dynamics—how the state moves forward in time if there were no external inputs or noise.
- Role in the equation: In
the term is your prediction of the new state based sData Fusion and Kalman Filterolely on the old one.
- Intuition:
- If your state is just a 1D position and you assume it doesn’t change by itself, .
- If your state is under a constant‑velocity model, then with timestep :
because (from kinematics)
and (from constant velocity assumption)
- Details: suppose our state at some timestep , then
which matches above.
Q: So we have to derive ourselves every time we need to apply a kalman filter?
:Control‑Input Matrix
- What it is: A matrix that describes how your known inputs or controls (e.g. commanded acceleration, wheel‑encoder speeds) push the state forward.
- Role in the equation: In
the term injects the effect of your control actions.
- Intuition:
- If your control is a direct velocity command in a 1D position‑only model, you might set
so that updates your position.
- In the 2‑state constant‑acceleration model, if is acceleration , you’d choose
because
Summary
- tells you “where the system would go on its own.”
- tells you “how external commands or controls nudge it.”
Observation Equation
This is just like our earlier example of measuring the coin’s diameter: it describes how we observe the system’s state. In SLAM, however, the observation is often indirect and mediated by an observation model. For instance, in visual‑inertial odometry (VIO) we want to estimate the system’s 6 DOF pose, but what the camera actually gives us are pixel coordinates of feature points, not the pose itself. Those pixel measurements are related to the 6 DOF state through the camera’s projection model. In other words, the projection model ties the actual observed pixel values to the true pose, and that relationship is our observation equation.
In summary, although the observation equation doesn’t measure the system state directly, it indirectly measures it via the observation model, so it still constitutes a measurement of the state.
Likewise, observations are noisy: feature‐point locations may be imprecise, and the projection model itself might not be perfect. Therefore we add Gaussian noise to the observation equation, and it must be Gaussian, because that assumption is necessary for deriving the Kalman Gain.
Intuition: At each time step , you get a new sensor reading . The Kalman‐filter observation equation
says that:
-
is the true system state at time (e.g.\ position/velocity, 6‑DOF pose, etc.).
-
is the observation matrix (or model) that tells you how the state maps into whatever your sensor actually measures.
- If your state is but your sensor only reads position, then
so that .
- In a camera case, would be the projection from 3‑D pose into pixel coordinates.
- is the measurement noise, capturing all the ways your sensor might err (electronic noise, quantization, feature‐extraction error, etc.). We model it as
meaning zero‑mean Gaussian with covariance . The size and shape of encode how much trust you place in that sensor—and whether different measurements are correlated.
Example of System State-Space Equations
Suppose we have a small car equipped with:
- A single‑line laser rangefinder that measures its distance from the starting point, and
- A wheel encoder that measures the wheel’s speed. Our goal is to estimate the car’s state, so we can write its state-space model like so:
State Equation
We want to arrive at something in this form
Start: Recall the discrete‐time kinematic update:
but we only measure velocity with noise:
- the measured velocity at time ,
- the zero‐mean process noise on that velocity.
Plug that into the kinematic step:
After distributing the ,
We can then match it to
- since , it follows that
- likewise , and
- and
Note: You always start with your true (possibly nonlinear) update, then group all deterministic terms into and bundle every approximation or uncertainty into the additive “noise” term .
Observation Equation
In our running example the sensor reads position directly, so
and hence .
Note: “starting point” for your observation equation always comes from your sensor model. In other words, from how the sensor actually measures the thing you care about. In general you write:
where:
- is the true (possibly nonlinear) mapping from state → sensor reading,
- is the additive measurement noise.
Summary
- : With no inputs and no noise you’d stay in place.
- : Converts encoder‐measured velocity into position change.
- : Process‐noise on the motion model (e.g. wheel slip) enters through .
- : The laser directly measures position.
- : Measurement‐noise on the laser reading.
Note: In the setup above, we put the wheel‑encoder measurement into the state equation (as the control input ) and the laser measurement into the observation equation. You might wonder: aren’t both sensors just making observations? Why not treat the wheel encoder like any other measurement? In fact, these two choices are mathematically equivalent.
- Wheel encoder in the state equation:
- You model its noise as part of the process noise acting on the control input .
- Wheel encoder in the observation equation:
- You set in the state equation and propagate velocity purely via the previous state, then treat the encoder reading as a second measurement that constrains the velocity in the observation equation.
Both formulations impose the same information on the filter; they simply differ in whether you view the encoder as an “input” or a “measurement.”
Kalman Filter
What does a Kalman filter do?
Despite its name, the Kalman Filter isn’t really a “filter” in the signal‐processing sense but a state estimator. Its job is to combine your state equation
and your observation equation
to produce the statistically optimal estimate of the true state (i.e.\ minimum‑variance unbiased).
Two Key Assumptions
- Linearity: Both the state‐transition model and the observation model must be linear in the state variable—hence the constant matrices and .
- Gaussian Noise: Both the process noise and the measurement noise are assumed zero‑mean Gaussian. Only under these two conditions does the algebraic derivation of the Kalman Gain guarantee that the fused estimate achieves the minimum possible error covariance in a purely statistical sense.
Kalman Fitler Intuition
Because we have two noisy estimates of the same state
- from the model (state equation), and
- from the sensor (observation equation) we fuse them exactly as we did when averaging two coin‐diameter measurements, choosing weights to minimize the final variance.
Derivation
- State equation (the “calculated” or predicted estimate)
Since is zero‐mean, we replace it by its expectation (zero) when forming the prior estimate:
- Observation equation (the “measured” estimate)
Likewise, has zero mean, so to get a direct state estimate from the measurement we momentarily ignore and invert :
Why “zero out” the noises and invert ?
-
Zero‐mean noise: In reality and aren’t zero, but we only know their statistics. If we had the actual noise values we wouldn’t need a filter, we’d just plug them in. Hence in the derivation we substitute the mean of each noise term (zero).
-
Inverting : This step is purely for intuition, to view the sensor’s reading as a “direct” state estimate. The final Kalman‐filter update never explicitly computes ; instead it uses a gain matrix that blends prediction and measurement optimally. Applying the data‑fusion idea, we simply form a weighted average of the predicted state and the measured state, like this:
Kalman Filter Task: Using the State equation and Observation equation to get the optimal state estimation
- State equation (calculated):
- Observation equation (measured):
By algebraically manipulating that weighted‑average formula, eliminating the need to explicitly invert :
We start with the weighted-average fusion:
- is your prior (predicted) state,
- is your measured state (i.e.\ ),
- is the matrix of weights you’ll choose (analogous to the scalar in the coin example).
- is the complementary weight on the prior.
We then substitute in the direct measurement form, since ,
Regroup to expose the “innovation” . Add and subtract inside:
Notice that
The vector is called the innovation or measurement residual—it’s how much the actual sensor reading differs from what your prediction would imply.
Define the Kalman gain , let
Then the update becomes the classic Kalman‐filter form:
- is your prior,
- is the innovation,
- is the gain that determines how much of that innovation you trust.
Summary
- You start by imagining “let’s just weight‐average” prediction vs. (inverted) measurement.
- Realize that weighting the direct measurement is equivalent to adding a correction proportional to the difference between what you saw and what you expected .
- That proportionality matrix is exactly the Kalman gain .
Choosing to minimize the posterior covariance is what makes the Kalman filter “optimal” in the minimum‑variance sense.
By applying the data‐fusion idea, our ultimate goal is to find a suitable weighting coefficient so that the final weighted‐average result has the smallest variance. For a multivariate random variable, this means minimizing the trace of its covariance matrix. As shown below: 2. Posterior update (weighted‐average fusion)
- : prior (predicted) state
- : new measurement
- : observation matrix
- : gain matrix (to be determined)
- Posterior covariance Denote the resulting covariance of by .
- Optimization criterion i.e. choose to make the trace of the posterior covariance as small as possible.
- Covariances in play
- Prediction covariance:
- Measurement covariance: Putting it all together, the Kalman Gain is the weight that minimizes .
Note:
- The covariance of the predicted state, , is obtained by propagating the previous covariance through the state equation.
- The covariance for the observation equation, since we haven’t transformed measurements from observation space into state space (i.e. we didn’t compute any pseudo‑inverse of ), is simply the observation noise covariance .
Prediction covariance derivation: We have the true state update
and the prior (predicted) estimate
Define the prediction error
Propagate the error, substitute from the state‐equation:
Compute the prior covariance: By definition: In general, for any random column‐vector we define its covariance as
Since
- We let be the prediction error.
- Under the usual Kalman assumptions (zero‐mean process and measurement noise, and an unbiased filter), that error itself has zero mean, i.e.\ . Hence its covariance simplifies to
Thus we arrive at:
Using and the facts that and are uncorrelated, and , we get
Measurement covariance derivation Your observation equation is
Here, is defined to be the covariance of the measurement noise . Thus any time you fuse or weight in a new measurement, the amount of uncertainty that measurement brings in is exactly .
Kalman Gain
is very complicated lol, for full derivation: https://www.bilibili.com/video/BV1hC4y1b7K7/?spm_id_from=333.788&vd_source=1363e3b30e51ca9984f82492949f865b or https://blog.csdn.net/qq_42731705/article/details/129423983
For now we just use the result:
This choice of is exactly the weight matrix that minimizes the trace of the posterior covariance. 2. Posterior Covariance Update
Together, these two equations complete the Kalman‐filter “measurement‐update” step:
- You compute from your prior covariance , the observation model , and the measurement‐noise covariance .
- You then update the covariance to , which is guaranteed to be the minimum‐variance (i.e. minimum trace) posterior under the linear‑Gaussian assumptions.
Summary
State‐Equation Prediction: Using the previous time step’s state and the system’s state‐space equation, we compute a prediction of the current state. At the same time, we update the covariance matrix of that predicted state: Definitions of all symbols assume , ,
(1) Prior estimation
- : prior (predicted) state estimate at time .
- : state‑transition matrix.
- : posterior state estimate at time .
- : control‑input matrix.
- : control (input) vector at time .
(2) Prior covariance
- : prior error‐covariance at time .
- : posterior covariance at time .
- : process‐noise covariance.
Observation‐Equation Update: First compute the Kalman Gain . Then treat as the weight to fuse the predicted state with the sensor’s measurement, yielding the optimal state estimate: (3) Kalman Gain
- : Kalman‐gain matrix.
- : prior covariance (from (2)).
- : observation matrix.
- : transpose of .
- : measurement‐noise covariance.
(4) Posteriori (updated) state estimate
- : Posterior (updated) estimate of the state at time .
- : Prior estimate (from Eq 1).
- : Kalman gain (from Eq 3).
- : Measurement vector at time .
- : Observation matrix.
(5) Posteriori covariance
- : posterior (updated) state estimate at time .
- : prior state estimate (from (1)).
- : Kalman gain (from (3)).
- : measurement vector.
- : observation matrix. Notice that the prediction is in units of the system state, while the measurement is in the sensor’s native units. Therefore the Kalman Gain carries physical units, it has the same units as .